继续研究Axum —— 初解agent和pipeline
写在前面:我也是刚刚接触包括actor模型在内的并行开发概念,所以理解有偏差的地方还希望看见的人可以给我指出来。共同前进。毕竟在我看来,这是我们的发展方向。
还是围绕核心的这句话。
“A .NET language for safe, scalable and productive parallel programming through isolation, actors and message-passing.”
在上一篇文章也在讲这句话,但是说穿了讲的应该是:
“A .NET language for parallel programming through message-passing.”
我们只是从一个channel中派生了一个agent,做了数据传递而已,真正意义上的actor在哪里没有讲到(虽然有用到)。那么这次讲一讲。因为刚好看到老赵的博客上好好的分析了actor模型一把,要好好向他学习啊。
Axum是为并行而生的.net语言,那么他提供了非常完整的Actor模型,使得每个actor可以安全的并发。那么不用说,coding的时候就肯定用到过了actor模型,究竟他在哪里呢?其实就是agent。还记得写Axum的第二篇文章,看到VS2008 generate出来的代码之后,看到agent的时候非常疑惑,那么现在就可以解惑了。
agent就是在axum中的actor模型。
讲到这里就很明显了,只是从channel派生出来的actor模型本身还肩负着其他功能。我想跟着Guide走,那么下一次也许还有机会讲到agent。
** 然后讲讲pipeline。先从一个程序出发:斐普纳吉数列的实现。**
首先是从Microsoft.Axum.Application这个channel中派生出一个agent —- MainAgent。
using System;
using Microsoft.Axum;
using System.Concurrency.Messaging;
agent MainAgent : channel Microsoft.Axum.Application
{
// ...
public MainAgent()
{
// ...
}
}
agent从channel中派生是种什么特殊情况呢?在Guide上是这么描述的:
Implementing a channel is different - syntactically and semantically - from deriving from a base agent. When an agent derives from another agent, it merely extends it by overriding some virtual methods, and potentially adding more of its own.
However, when an agent implements a channel (notice the channel keyword after the colon in the agent declaration), it "attaches" itself to the implementing end of that channel and becomes the "server" of messages on that channel. The other end of the channel - known as the using end - is only visible to the "client", or the component (typically another agent) on the other end of the channel. > >
大概翻译一下:(哪怕只当Guide翻译集锦看也好)
从一个channel派生和从一个接触agent中派生是不一样的,有字面上的和语义上的两种理解。一个agent从另一个agent从派生的话,只不过是通过覆盖重写它的方法或可能为自己增加更多的一种扩展。
然而当一个agent从一个channel派生的话,它是把自己”贴”到channel的派生端(implementing end),从而成为channel上的信息的”服务端”。而Channel的另一端(被称作应用端(using end))是指对”客户端”或在channel另一端的某个组件(代表性的就是另一个agent)。
channel负责传递信息,但是它不会对信息做任何处理。(处理的当然是agent啦)
那从Microsoft.Axum.Application这个channel派生的主程序是如何处理信息的呢?
The runtime instantiates the agent implementing channel Microsoft.Axum.Application, sends command line parameters to the channel’s CommandLine port, and then waits for a message on port ExitCode. When the message is received, the application shuts down.
从Microsoft.Axum.Applicationruntime这个Channel派生过来的agent的runtime实例,发送命令行参数到channel的命令行端口(CommandLine port),然后等待退出代码端口(prot ExitCode)的信息。当收到信息后,应用程序就关闭。
这样一个ax程序的运行机理也就知道了,如果说C是从main函数中得到参数,执行完毕后跳出。那ax程序就是从这个main channel出发,得到退出代码的信息后退出。
继续补充代码,然后来看看信息的异步编程。先写一个斐普纳吉的递归算法。
function int Fibonacci(int n)
{
if( n<=1 ) return n;
return Fibonacci(n-1) + Fibonacci(n-2);
}
然后是界面的代码。
int numCount = 10;
void ProcessResult(int n)
{
Console.WriteLine(n);
if( --numCount == 0 )
{
Console.ReadLine();
PrimaryChannel::ExitCode <-- 0;
}
}
这些都是无聊的部分了说。PrimaryChannel::ExitCode <– 0; 可以理解为跳出代码,就像前面说到的,给main channel(PrimaryChannel)ExitCode Port送去0,程序就退出了。至于ReadLine只是为了看到打印的10个结果而已。
之后就是最精彩的创建OrderedInteractionPoint和pipeline的代码了。
public MainAgent()
{
var numbers = new OrderedInteractionPoint<int>();
// Create pipeline:
numbers ==> Fibonacci ==> ProcessResult;
// Send messages to numbers:
for( int i=0; i<numCount; i++ )
numbers <-- 42-i;
}
从格式上看,微软工程师们还是很有创意的,这段代码看上去很有美感。值得说的东西也是非常的多。
Axum提供了两种orchestration(这单词怎么翻译?编排?)方式,基于控制流(control-flow-based)和基于数据流(data-flow-based)。
In Axum, the messages are sent to and received from the interaction points. An interaction point from which a message originates is called the source, and the destination is called the target. An interaction point can be both a source and a target, meaning that it can both send and receive messages. This allows composition of multiple interaction points into dataflow networks.
在Axum中,信息传递和接受是通过interaction points(互动点?)的。信息源的interaction point叫做source,目的地的叫做target。同一个interaction point能同时既作为source,又作为target,意味着它能同时发送和接受信息。这样就允许很多的Interaction point组成一个数据流网络。
翻译过来之后,意思应该已经比较清晰了,数据流和原始的控制流程序不一样,以前类似上面代码的过程,我们写完两个方法之后需要把一个先初始化两个数据,其中一个传入斐普纳吉计算然后一个去接受结果(不是唯一解决方法),然后再将结果去交给界面方法打印。而现在我们调用的过程就整个缩减为一个管道:
numbers ==> Fibonacci ==> ProcessResult;
numbers是创建的OrderedInteractionPoint,Ordered可以看出它是有顺序的,这个后面会讲到。当执行到numbers <– 42-i语句的时候,这个interaction point得到了信息,于是激发了管道内后面的function的运行。看上去的确很棒!
有了pipeline,我们就要使用它,因为axum在编译的时候对它是进行特殊处理的。比如斐普纳吉计算过程是a side-effect-free function,一个没有副作用的函数,那么axum就会根据它认为最有效的方式的方式编译出多个线程来处理,并行的优势就体现在这里。
之前说到Ordered,虽然这个数据流是可以并行执行的,但是它的顺序是不会发生变化的,哪怕多个实例在一个结点上,想进入下一个结点你也是必须执行完现在的节点的。就比如说上面的程序中,UI打印模块在你完成斐普纳吉计算前绝对不能新建线程。
程序代码和执行效果:
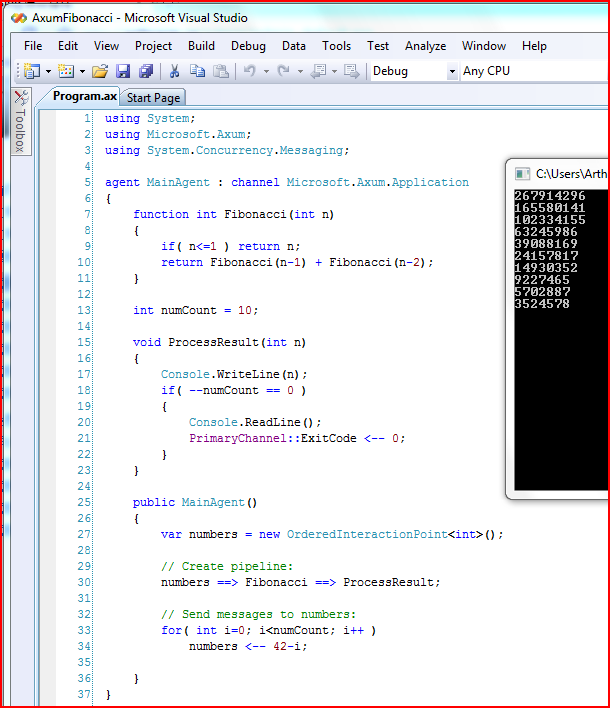
说到这里就把Axum的agent和pipeline都说完了。简单的总结起来,agent就是actor模型的实现,而pipeline就是基于数据流的程序驱动方式。
关于Axum的其他新特性,再慢慢研究咯~